
Our web archives are available online here.
In March 2020, the world began witnessing history in real-time, and archivists scrambled to ensure that the story of COVID-19 would be well-preserved. But with so much happening at a distance, much of the communication and ephemera created in the last six months is online, meaning that archivists have had to eschew traditional practices in collecting physical material and focus increasingly on the enormous amount of material now online. For example, at the peak of the crisis, healthcare institutions like Mount Sinai were updating their websites multiple times a day so that staff and the public had the best and most recent information on policies and procedures regarding things like new treatments and personal protective equipment. This type of information will be valuable moving forward as historians try to understand a rapidly evolving crisis.
Fortunately, technology exists to capture every version of these websites as they appear online. Web archiving has been a practice since the late-1990s, and since 2015 the Aufses Archives has used Archive-It, a web archiving service provided by the Internet Archive, to regularly capture information related to the Mount Sinai Health System. We also use this tool to capture web content related to the response to COVID-19, as well as day-to-day changes to the website.
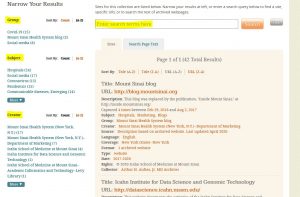
Screenshot of the Aufses Archives page on Archive-It.
The easiest way to access our web archives is to browse the list of websites on the main screen. These results can be filtered using the groups, subjects, or creators on the left side of the screen. You can also use the search bar at the top of the screen to search the metadata created by the archivist. (We expect our COVID-19 group to be the most used group for the foreseeable future.) Information on COVID-19, as well as a wide range of subjects, has been collected by a number other academic institutions, and you can also browse their collections here.
If you’re searching for a particular webpage instead of a whole website, or if you’re trying to search the original text of a website, the “Search Page Text” option may be of use. This feature supports keyword searching of individual web pages, much like Google. However, you can also filter by “Capture date range” which means you can search not just across subjects, but also across time.
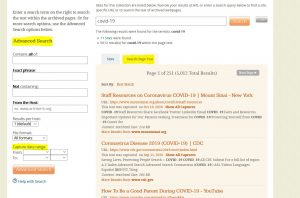
Screenshot of the “Search Page Text” functionality in Archive-It, after searching “COVID-19.”
With either searching method, once you’ve selected a link, you’ll be taken to a page of dates, each corresponding to a particular date of capture. While there’s no guarantee that every version of the website was captured, it will at least give you a sense of how the site has progressed over time.

This page, related to the COVID-19 pandemic, had 72 captures at the time of writing, starting every day from March 23, 2020, to May 12, 2020. The crawl now occurs monthly, due to fewer updates of the website.
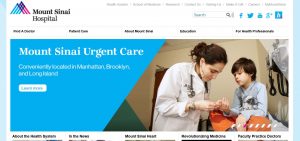
Once you’ve selected a date, you’re taken to a version of the website captured on that date. Shown below is our earliest Archive-It capture of the Mount Sinai Hospital homepage, as it appeared in February 2015. The website should play back in the same was as it originally appeared.
Of course, the Mount Sinai Health System only represents a very small corner of the internet, and archivists are working to capture as much as possible. All the websites captured by the Aufses Archives contribute directly to the Internet Archives’ Wayback Machine, which at the time of writing has 477 billion website captures, including a limited number of Mount Sinai webpages dating back to the 1990s, captured on an ad hoc basis. You can also contribute by adding URLs via the link on the Wayback homepage.
Authored by Stefana Breitwieser, Digital Archivist